AI crawleři stahující veřejný obsah
Pohled na to, jak AI společnosti stahují data a co s tím můžeme dělat.
Jakub Žitník
Autor
5 minut
Pohled na to, jak AI společnosti stahují data a co s tím můžeme dělat.
V poslední době spousta společností začala trénovat vlastní AI modely. AI modely potřebují data. Hodně dat. Jakože HODNĚ.
Jak tyto společnosti získávají všechna tato data? Je legální nebo morální, aby stahovali celý internet? A jak tomu zabránit? O tom budu mluvit v tomto příspěvku.
Jsem Full-Stack Web Developer. Dělám weby pro klienty a hostuji spoustu věcí na internetu. Vidím čím dál více AI botů, kteří stahují můj web, a rozhodl jsem se zjistit, jak je využívají a jestli to není problém.
Poznámka: Všechny sdílené informace jsou z mé vlastní zkušenosti a výsledky se mohou lišit robot od robota a společnost od společnosti.
Hostuji vlastní Gitea instanci. Gitea je webová aplikace pro hostování kódu, podobně jako GitHub. Moje Gitea běží za Cloudflare tunelem, takže snadno vidím, jaké požadavky přicházejí, z jakých IP adres a hlavně s jakým User-Agentem.
Z mé zkušenosti AI scrapeři stahují hlavně kód hostovaný na mé Gitea. Také ale stahují moje příspěvky nebo jiné textové věci.
Toto je přehled AI crawlerů, kteří stahovali můj web za posledních 24 hodin podle Cloudflare.
| Bot name | Company | Requests (24h) |
|---|---|---|
| AmazonBot | Amazon | 8.35k |
| Meta-ExternalAgent | Meta | 1.8k |
| Bytespider | ByteDance | 334 |
| ClaudeBot | Anthropic | 21 |
| PetalBot | Huawei | 16 |
| TikTok Spider | ByteDance | 6 |
| CCBot | Common Crawl | 4 |
| Claude-SearchBot | Anthropic | 1 |
Všimněte si, že toto jsou jen ti poctivější boti, kteří uvádějí své jméno v User-Agent hlavičce. Někteří to obvykle nedělají.
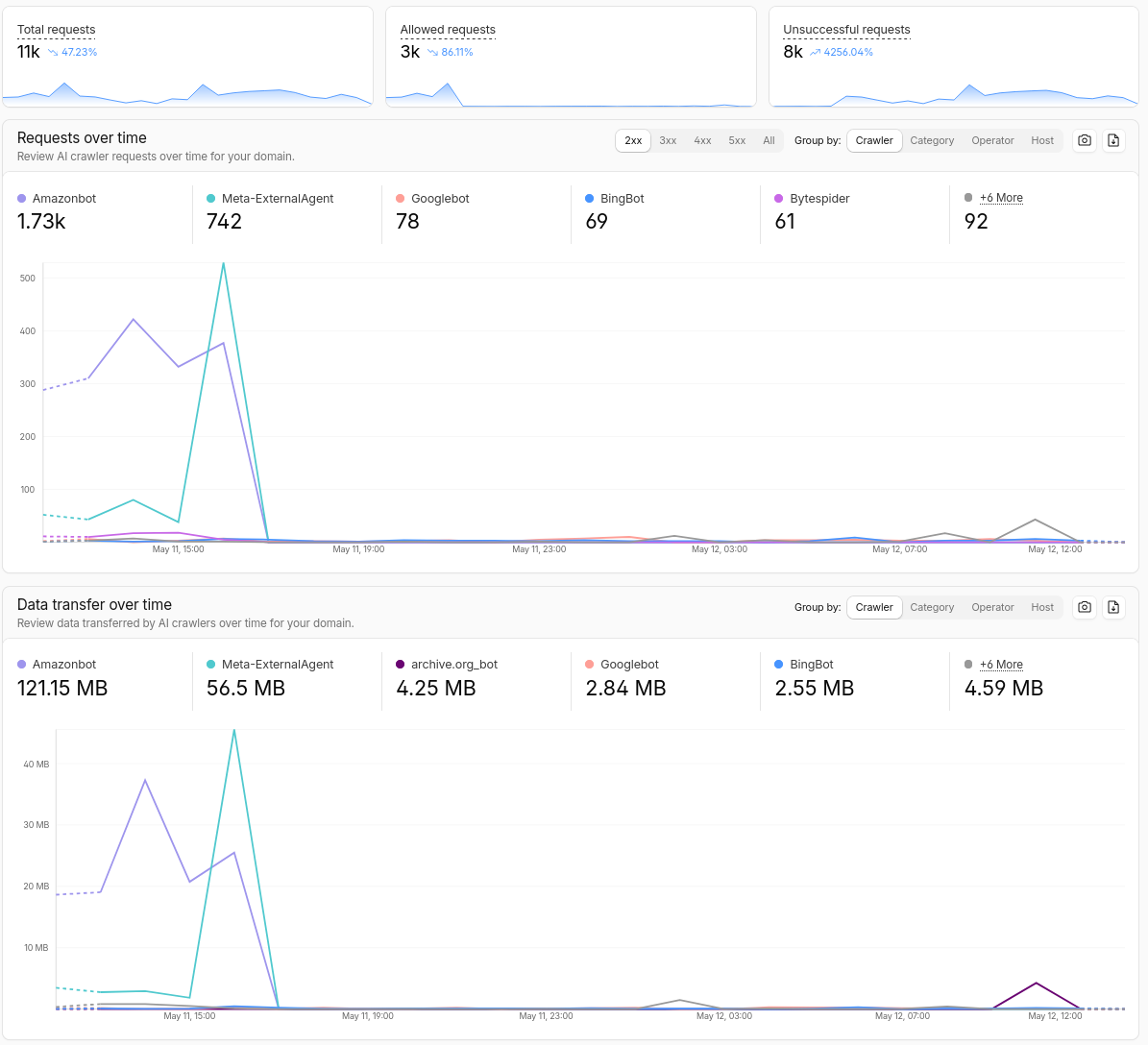
Existují boti, kteří své jméno v User-Agent hlavičce neuvádějí. To je ten největší problém ze všech. Těžko se blokují, protože obvykle přicházejí s platnou User-Agent hlavičkou prohlížeče. Také přicházejí z různých IP adres z mnoha lokací.
Omezení jako Cloudflare “Under attack” režim také nejsou ideální. Uživatelé nesnáší tu captchu, kterou musí vyplnit, než se dostanou na web. Toto může také zablokovat boty, kteří jsou pro vás užiteční, například vyhledávače.
Na hodinu jsem zapnul logger, který zaznamenával všechny požadavky na mou Gitea instanci. Chtěl jsem vidět, jaké požadavky přicházejí. Zde můžeme vidět pěkný příklad AI crawlera, který není upřímný.
GET https://gitea.jzitnik.dev/jzitnik/game/commit/a6cc33bbac23c8998c8b514e26ee49aede1552b6.patch
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET4.0C; .NET4.0E)
Toto není skutečný uživatel stahující patch z mé hry. Toto je bot, který se dívá na můj kód, aby trénoval AI modely. Jak to vím? User-Agent hlavička prozrazuje vše:
Takže v podstatě je to bot na Windows 7 používající MS Explorer 10, který se tváří jako MS Explorer 7. Toto není skutečný uživatel. Je to bot předstírající, že je člověk. Staré řetězce prohlížečů používají kvůli kompatibilitě — staré stránky jsou pro boty často snadněji čitelné.
AI crawleři nejsou jediný typ crawlerů, které na svém webu nechcete. Viděl jsem boty, kteří dělali požadavky na cesty jako:
/dostshell.php/xfile25.php/wp-block.php/wp-includes/theme-compat/wp-login.phpToto jsou automatizované bezpečnostní skeny. Jsou to škodlivé boty. Snaží se najít web shell nebo zranitelnost ve starém CMS jako je Wordpress. Toto je na internetu běžné, ale je zajímavé vidět, jak časté to je. Tyto požadavky přišly z Microsoft Azure IP, takže útočník jen používá VPS.
Jedna věc, kterou si mnoho lidí neuvědomuje, je, jak AI scraping mění celý internet pro vývojáře. Vezměte si Reddit nebo Twitter (X). Tyto sociální sítě mívaly zdarma nebo levná API, která vývojáři mohli používat k tvorbě aplikací.
Ale když je AI společnosti začaly stahovat kvůli datům, tyto platformy se naštvaly. Nechtěly, aby AI společnosti získávaly jejich data zadarmo. Takže uzavřely svá API nebo je velmi prodražily. To je pro nás špatné. Malí vývojáři si tyto vysoké ceny už nemohou dovolit. AI společnosti způsobily, že se kolem internetu zvedly “zdi”.
Existuje také děsivý problém zvaný “Model Collapse” (kolaps modelu). Pokud každý web začne blokovat AI boty, nebo pokud lidé přestanou psát a používají jen AI k psaní, pak AI začne stahovat obsah, který už byl vytvořen AI.
Je to jako had požírající vlastní ocas. Pokud AI trénuje na datech z jiné AI, začne být “hloupější” a dělá více chyb. Ztrácí lidský dotek. Tím, že dnes všechno tak rychle stahují, tyto společnosti možná ničí kvalitu dat, která budou potřebovat v budoucnu.
Podle mě je nejjednodušší způsob boje tento:
Technicky je tento obsah veřejný. Ale veřejný neznamená, že ho může kdokoli použít k čemukoli. Vše na internetu má licenci. Myslíte, že tyto AI společnosti respektují licenci vašeho projektu? Ne.
AI společnosti se nestarají o vaše data, vaši licenci ani váš robots.txt soubor. Některé jsou lepší než jiné, ale v podstatě žádná AI společnost nerespektuje vaše soukromí ani vaše vlastnictví. Trénují na vašich datech a pak vám účtují peníze za používání modelu, který postavily na vašich datech. Připadá mi, jako by vám je ukradli.
Mluvil jsem hodně o špatných botech, ale někteří boti jsou dobří. Jsou to vyhledávačové boty.
Tito boti procházejí váš web, aby ho mohli zobrazit na Google nebo Bingu. To je užitečné. Chcete, aby lidé našli váš web. Tito boti nekradou váš obsah, aby vytvořili konkurenční produkt. Jen čtou metadata, aby zjistili, jak relevantní je váš web pro vyhledávání.
Abych to shrnul, je velký rozdíl mezi dobrými a špatnými boty. Vyhledávačové boty chceme, protože pomáhají lidem najít naše weby. Ale AI crawleři jen berou naše data bez ptaní. Chtějí použít naši práci k vytvoření svých vlastních placených produktů a nerespektují naše licence.
Jako lidé, kteří tvoří věci na internetu, musíme chránit své projekty. Můžete použít robots.txt, Cloudflare nástroje nebo blokování User-Agent k jejich zastavení. Internet je o otevřeném sdílení, ale tyto AI společnosti nehrají fér. Dokud nezačnou respektovat naši práci, měli bychom se je snažit blokovat, abychom ochránili svá data.