AI crawlers scraping public content
A look into how AI companies scrape data and what we can do to stop it.
Jakub Žitník
Author
6 minutes
A look into how AI companies scrape data and what we can do to stop it.
Recently a lot of companies have started training their own AI models. AI models need to be trained on data. On a lot of data. Like A LOT.
How are these companies getting all this data? Is it legally or morally okay for them to scrape the internet? And how to stop it. That is what I am going to talk about in this post.
I am a Full-Stack Web Developer. I make websites for clients and I host a lot of stuff on the internet. I see more and more AI bots scraping my website, and I decided to search and learn about their usage and potential wrong doing.
Note: All of info shared are from my experience, and the results may vary bot to bot and company to company.
I host my own Gitea instance. Gitea is a website that you can use for hosting your code, similar to GitHub. I serve my Gitea behind a Cloudflare tunnel so I can easily see what requests are being made, from what IP addresses and most importantly with what UserAgent.
From my experience, AI scrapers scrape mostly code hosted on my Gitea. They also like to scrape my posts or other text-based stuff.
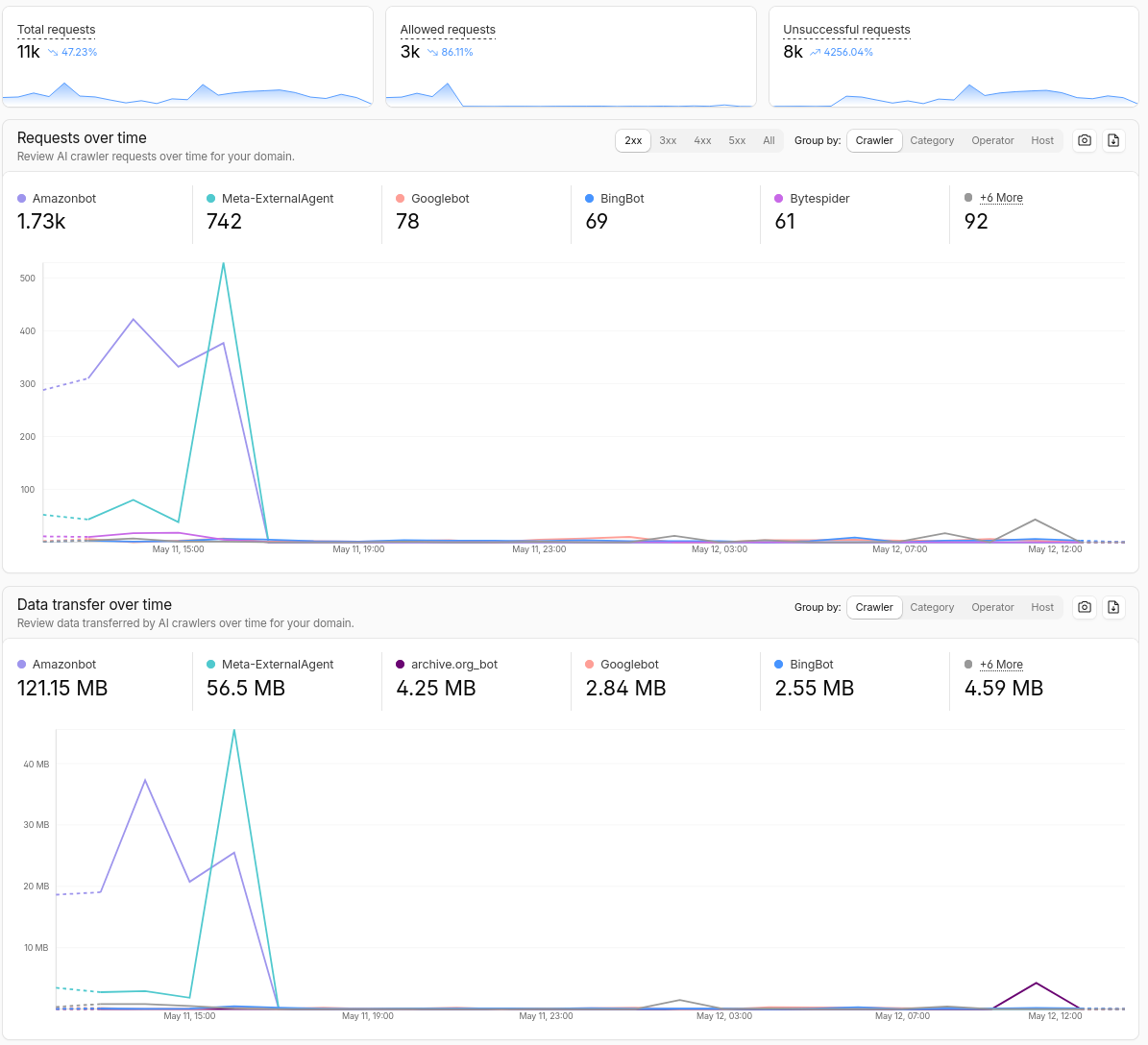
This is what AI Crawlers were scraping my website in the last 24 hours according to Cloudflare.
| Bot name | Company | Requests (24h) |
|---|---|---|
| AmazonBot | Amazon | 8.35k |
| Meta-ExternalAgent | Meta | 1.8k |
| Bytespider | ByteDance | 334 |
| ClaudeBot | Anthropic | 21 |
| PetalBot | Huawei | 16 |
| TikTok Spider | ByteDance | 6 |
| CCBot | Common Crawl | 4 |
| Claude-SearchBot | Anthropic | 1 |
Note that these are only the more honest bots that include their name in their User-Agent. Some usually do not.
There are bots that do not include their name in their User-Agent Header. This is the biggest problem out of all of them. You cannot really block those easily because they usually come with a valid browser User-Agent Header. They also come from different IP addresses from many locations.
Restrictions like Cloudflare “Under attack” mode are not good either. Users hate that captcha they have to fill before going to your website. This can also block bots that are actually useful for you, like search engine bots.
I added a logger just for an hour to log all the requests made for my Gitea instance. I wanted to see what requests are made. Here we can see a nice example of an AI crawler that is not honest.
GET https://gitea.jzitnik.dev/jzitnik/game/commit/a6cc33bbac23c8998c8b514e26ee49aede1552b6.patch
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET4.0C; .NET4.0E)
This is not a real user fetching a patch from my game. This is some bot looking at my code to train AI models. How do I know? The User-Agent header tells the story:
So basically, it is a bot on Windows 7 using MS Explorer 10 that acts as MS Explorer 7 to load a “legacy” webpage. This is not a real user. It is a bot pretending to be a human. They use old browser strings for compatibility because old pages are often easier for bots to read.
AI Crawlers are not the only type of crawlers you do not want on your website. I saw some bots making requests to paths like:
/dostshell.php/xfile25.php/wp-block.php/wp-includes/theme-compat/wp-login.phpThese are automated vulnerability scans. These are malicious bots. They try to find a web shell or a vulnerability in an old CMS like Wordpress. This is normal on the internet, but it is interesting to see how common it is. These requests came from a Microsoft Azure IP, so the attacker is just using a VPS.
One thing that many people missed is how AI scraping is changing the whole internet for developers. Think about Reddit or Twitter (X). These social media used to have free or cheap APIs that developers could use to make apps.
But when AI companies started scraping them to get data, these platforms got angry. They did not want AI companies getting their data for free. So, they closed their APIs or made them very expensive. This is bad for us. Small developers cannot afford these high prices anymore. AI companies caused the “walls” to go up around the internet.
There is also a scary problem called “Model Collapse.” If every website starts blocking AI bots, or if humans stop writing and only use AI to write, then AI will start scraping content that was already made by AI.
It is like a snake eating its own tail. If an AI trains on data from another AI, it starts to get “dumb” and makes more mistakes. It loses the human touch. By scraping everything so fast today, these companies might be destroying the quality of the data they need for the future.
The easier way in my opinion to fight this is:
Technically, this content is public. But public does not mean anyone can use it for everything. Everything on the internet has a license. Do you think these AI companies respect the license on your project? No.
AI companies do not care about your data, your license, or your robots.txt file. Some are better than others, but basically no AI company respects your privacy or your ownership. They train on your data, then they charge you money to use the model they built with your data. It feels like they stole it.
I have talked a lot about bad bots, but some bots are good. These are Search Engine bots.
These bots go through your website so they can show it on Google or Bing. This is useful. You want people to find your website. These bots do not steal your content to build a competing product. They just read metadata to calculate how relevant your website is for a search.
To sum it up, there is a big difference between good bots and bad bots. We want search engine bots because they help people find our websites. But AI crawlers just take our data without asking. They want to use our work to make their own paid products and they do not respect our licenses.
As people who make things on the internet, we need to protect our projects. You can use your robots.txt, Cloudflare tools, or block User-Agents to help stop them. The internet is meant for open sharing, but these AI companies are not playing fair. So until they start respecting our work, we should try to block them to protect our data.